TensorRT는 NVIDIA GPU상에서 모델의 추론 속도를 최적화해 주는 프레임워크이다.
TensorRT 최적화 방식
TensorRT는 GPU의 cuda 코어에서 시행된다. cuda는 GPU와 직접 통신하기 위한 API에 해당한다. (cudo 코어와 유사하게 Tensor 코어 방식이 있지만 구글 직원이 아니라면 TPU 배포는 좋은 선택지는 아닐 수 있다.) TensorRT는 다음 그림에 소개된 크게 6가지 방식으로 최적화를 수행한다.

위에서 몇가지만 살펴보면 Kernel Auto-tuning은 Cuda 드라이버에 맞춰 최적의 런타임을 생성할 수 있도록 한다. GPU 플랫폼 기반으로 최상의 레이어와 알고리즘, 최적의 배치 크기를 선택하는 방식이다. Laye & Tensor Fusion은 Tensor Fusion을 이용해 커널의 노드를 수직 또는 수평으로 융합해 GPU 메모리와 대역폭을 최적화해, 각 계층에 대한 텐서 데이터를 읽고 쓰는 오버헤드 비용을 낮추는 방식이다.
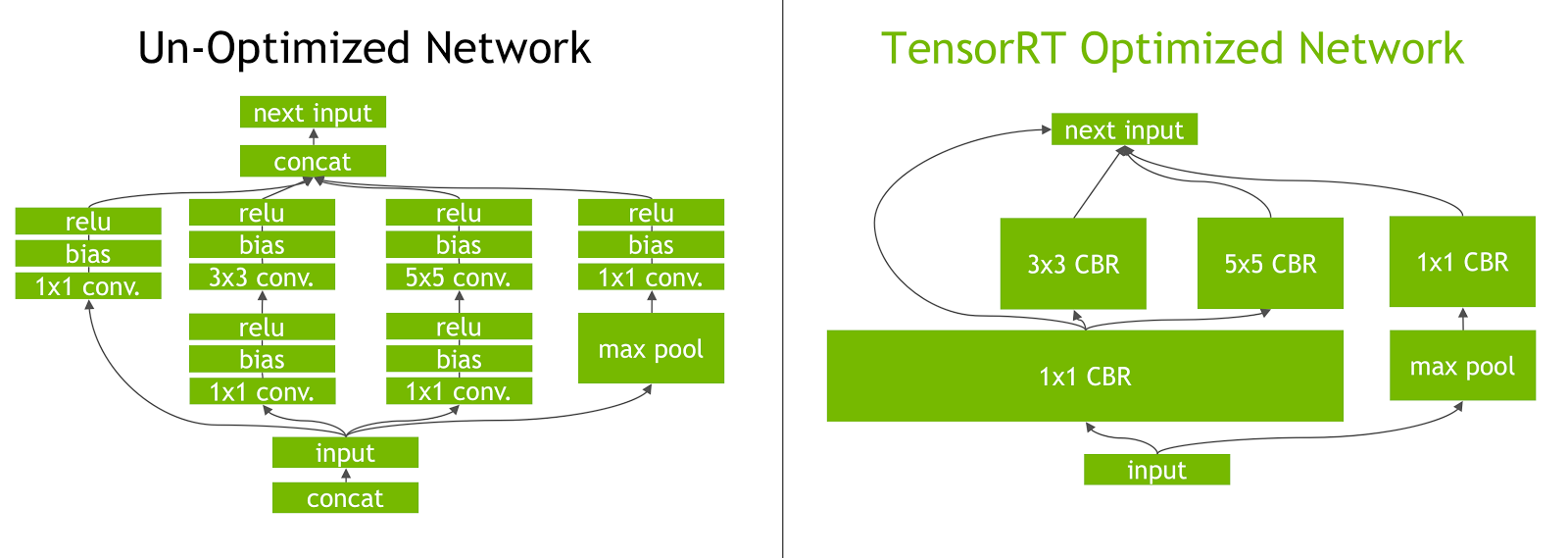
Dynamic Tensor memory는 Tensor에 사용 기간동안에만 메모리를 할당해 메모리 재사용을 개선하는 방식이다. Multi-Stream Execution이라는 방식은 여러 스트림을 병렬로 처리 하는 방식이다. GPU가 지원하는 활용 가능한 연산을 자동으로 사용할 수 있도록 실행 바이너리를 빌드해 주기에 Latency와 Throughput 향상이 가능하다.
TensorRT 호환
TensorRT는 C++또는 Python API를 제공해 Caffe, ONNX 또는 TensorFlow 모델을 가져올 수 있도록 제공한다. 또한 Pytorch나 TensorFlow에 직접 통합이 가능하다. 예를 들어 Pytorch는 Torch-TensorRT를 사용해 통합이 가능하고, Tensorflow는 Tensorflow-TensorRT를 이용해 통합이 가능하다. TensorRT는 GPU 추론 가속에 사용할 수 있다. 만약 CPU 추론 최적을 목표로 한다면 OpenVINO 및 ONNX 프레임워크 프레임웍 확인이 필요하다.