MLOps에서 모델 서빙
MLOps에서 모델 서빙은 운영 중인 머신 러닝 모델을 사용자와 상호작용할 수 있도록 만들어주는 프로세스입니다. 이는 모델의 성능, 안정성, 신뢰성을 보장하고, 실시간으로 모델을 업데이트하고 모델의 예측 결과를 모니터링할 수 있도록 해줍니다. 서빙은 대체로 세가지 기능을 포함할 수 있어야합니다.
-
사용자의 상호 작용 기능 : 모델 서빙은 사용자와의 상호작용 기능을 제공합니다. 이를 통해 모델이 실제 환경에서 사용되는 방식을 고려할 수 있습니다. 사용자의 요구사항에 따라 모델을 조정하고, 더 나은 성능을 위해 모델을 개선할 수 있습니다.
-
모델 업데이트 기능 : 모델 서빙은 실시간 업데이트 기능을 제공합니다. 새로운 데이터가 들어오면, 모델을 업데이트하고 새로운 예측 결과를 제공할 수 있습니다. 이는 모델이 변화하는 환경에서 유연하게 대응할 수 있도록 해줍니다.
-
모델 모니터링 기능 : 모델 서빙은 모델의 안정성과 신뢰성을 보장하는데 중요한 역할을 합니다. 모델 서빙은 모델의 예측 결과를 모니터링하고, 이상 현상이나 장애가 발생하면 이를 탐지하고 대응할 수 있도록 해줍니다. 이는 모델을 운영 중인 시스템의 안정성을 유지하는 데 도움을 줍니다.
모델 서빙은 MLOps에서 매우 중요한 역할을 합니다. 사용자와의 상호작용 기능, 실시간 업데이트 기능, 모니터링 기능을 제공하여 모델의 성능, 안정성, 신뢰성을 보장하고, 운영 중인 시스템의 안정성을 유지하는 데 도움을 줍니다.
모델 서빙의 종류
모델 서빙 프레임워크는 머신러닝 모델을 시시간으로 예측하기 위한 도구 모음입니다. 모델 서빙 프레임워크는 다양한 모델 포맷을 지원하며, 학습된 모델을 서버에 포팅해 서비스 형태로 제공한다. 대표적인 서빙 프레임워크로 다음과 같은 것들이 있습니다.
| 종류 | 회사 | 모델 포맷 | 속도 | 장단점 |
|---|---|---|---|---|
| TensorFlow Serving | TensorFlow, Keras, SavedModel | 높음 | 분산 시스템을 지원하며, TensorFlow 모델을 위해 최적화 되어있음. | |
| Triton Inference Server | Nvidia | TensorFlow, TensorRT, ONNX | 매우 높음 | 다양한 모델 포맷을 지원하며, GPU 가속을 통해 빠른 서빙 가능. |
| TorchServe | PyTorch, TorchScript | 중간 | PyTorch 모델을 위해 최적화 되어있으며, 다양한 모델 포맷을 지원. | |
| BentoML | BentoML | 다양한 | 중간 | 모델 서빙뿐만 아니라, 모델 빌드, 테스트, 배포를 종합적으로 제공. 다양한 프레임워크와 클라우드 서비스를 지원하며, 코드 중복을 최소화할 수 있음. |
| MLflow | Databricks | 다양한 | 중간 | 모델 학습, 추적, 서빙을 포함한 엔드 투 엔드 기계 학습 플랫폼. 다양한 프레임워크와 클라우드 서비스를 지원하며, 모델 버전 관리와 협업 기능을 제공. |
위에 언급 되지 않았지만 Cortex, KFServing, Multi Model Server, ForestFlow, DeepDetect, Seldon Core,DeepSparse 등이 존재합니다. 이러한 모델 서빙 프레임워크를 사용하여 모델을 배포하고 예측을 수행할 수 있습니다.
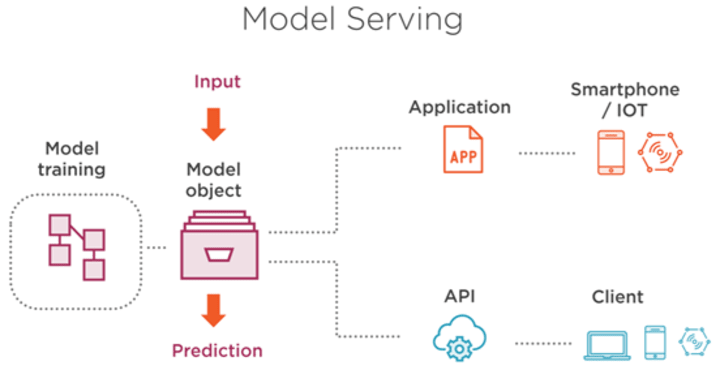
이어서 주요 서빙 프레임워크에 대해서 간단히 소개를 드리고자 합니다. 서빙 프레임워크 마다 분명 장단 점이 존재하기 때문에, 각 서빙 프레임워크의 장단점을 고려해서 사용하면 될것 같습니다.
Triton Inference Server
Triton Inference Server는 Nvidia에서 개발한 오픈소스 모델 서빙 프레임워크입니다. 다양한 모델 포맷(TensorFlow, TensorRT, ONNX)을 지원하며, GPU 가속을 통해 빠른 추론(inference)을 제공합니다. Triton Inference Server의 장단점은 다음과 같습니다.
장점:
- 매우 높은 서빙 속도
- 다양한 모델 포맷을 지원
- TensorRT와 같은 Nvidia의 최적화 엔진을 사용하여 높은 추론 성능을 제공
단점:
- Nvidia GPU에 최적화되어 있어서 다른 GPU 또는 CPU에서의 성능은 상대적으로 떨어질 수 있음
- TensorFlow Serving과 같은 대중적인 모델 서빙 프레임워크와는 다르게 상대적으로 새로운 기술이기 때문에 커뮤니티와 문서가 상대적으로 덜 발전되어 있을 수 있음.
Torch Serve
orchServe는 PyTorch 모델의 서빙을 위한 오픈소스 모델 서빙 프레임워크이다. 다양한 모델 포맷(PyTorch, TensorFlow, ONNX)을 지원하며, 커스터마이즈가 용이하고 높은 성능을 제공합니다. TorchServe의 장단점은 다음과 같습니다.
장점:
- PyTorch로 훈련된 모델에 대한 원활한 서빙을 지원
- 다양한 모델 포맷을 지원
- 커스터마이즈가 용이하고 사용자 정의 모델을 쉽게 추가할 수 있음
- 비교적 직관적인 API를 제공하며, 높은 서빙 성능을 제공함
단점:
- TensorFlow 2.x의 SavedModel 형식을 지원하지 않음
- 실시간 모델 업데이트 기능이 아직 충분히 발전하지 않음
BentoML
BentoML은 머신러닝 모델을 서빙하기 위한 프레임워크 중 하나로, 모델 서빙과 관련된 전반적인 문제를 해결하는 플랫폼이다. BentoML의 장단점은 다음과 같습니다.
장점:
- 다양한 머신러닝 프레임워크(PyTorch, TensorFlow, Scikit-learn 등)에서 생성된 모델들을 지원
- 커스텀 모델 서빙 파이프라인을 쉽게 작성하고 관리할 수 있음
- 배포된 모델에 대한 추적, 모니터링, 로깅 및 메트릭 수집을 지원
- 높은 수준의 모델 버전 관리 및 관리도구
- 클라우드 서비스 및 Kubernetes와 같은 대규모 클러스터에서 배포 가능
단점:
- 다른 서빙 프레임워크와 비교했을때 상대적으로 높은 학습 곡선
- 일부 모델 포맷 및 옵션 지원이 부족할 수 있음