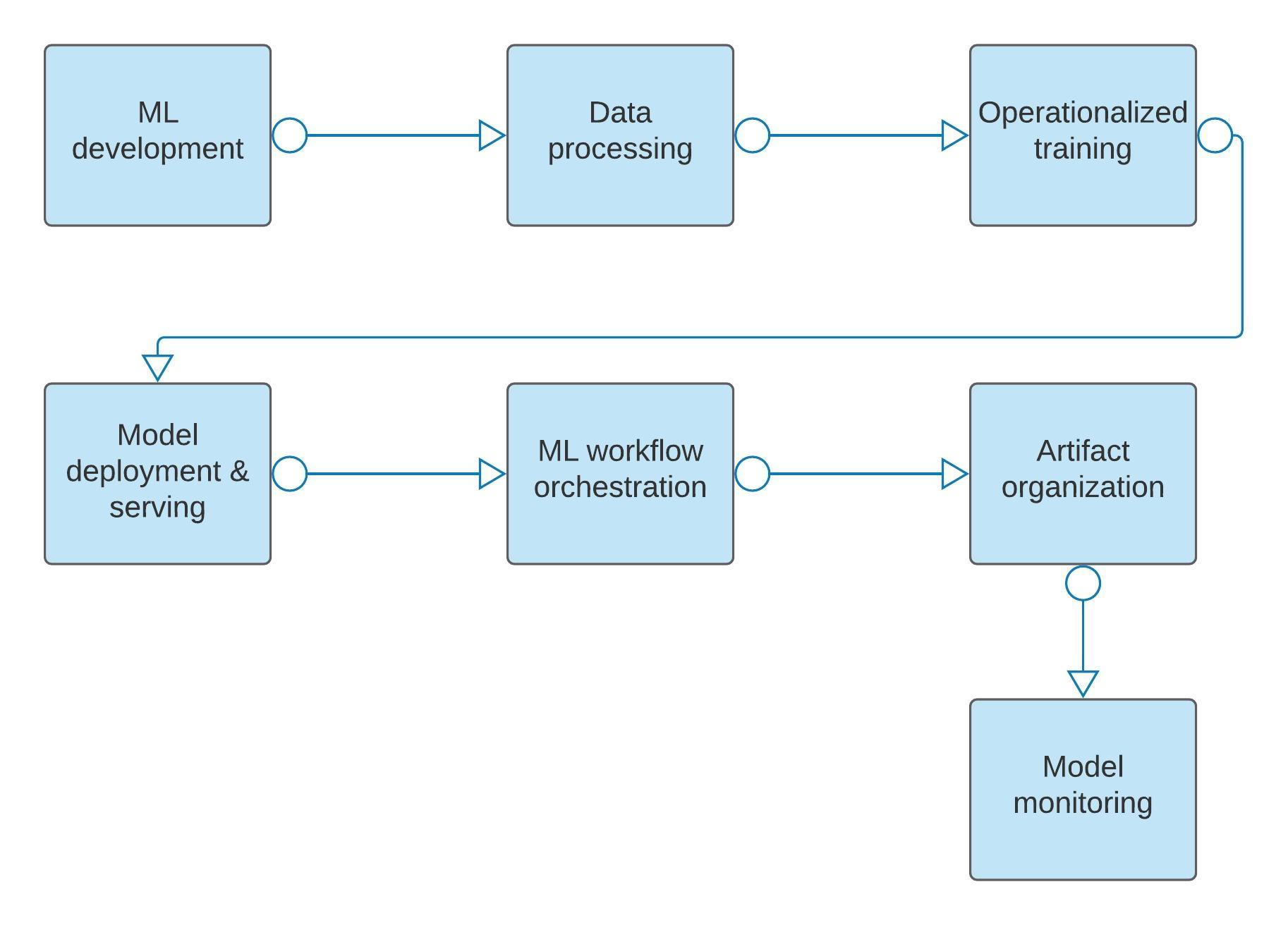
AI 시스템은 머신러닝 모델의 생성에 필요한 서버 환경을 바탕으로 데이터 관리, 모델 관리, API 인터페이스를 제공하는 시스템이다. AI 시스템이 안정적인 서비스를 제공하려면 신뢰성과 확장성을 바탕으로 한다.
하나의 AI 시스템은 추천 모델, 언어 모델, 음성 모델 등 다양한 모델들을 운영한다. 이것은 서비스 관점에 따라서 상이한 모델을 호출해서 사용하기 때문이다. 여러 모델을 하나로 합치려는 방식도 있지만, 이는 현실적으로 어려운 점이 있다. 머신러닝 모델을 실재 상용에 운영하기 위해서는 기본적인 규모 있는 데이터를 관리할 수 있어야 하고, 이를 바탕으로 머신러닝 모델을 생성할 수 있어야 한다. 데이터 관리의 경우 최근 불거진 데이터 윤리 문제와도 무관하지 않다. 데이터 윤리를 고려한 데이터 설계가 필요하며, 이를 바탕으로 한 데이터 관리를 해야 한다. 성차별, 윤리 문제등 사회 이슈로 쟁점화 되지 않도록 데이터를 관리하고 학습한 머신러닝 모델이 상업적으로 제약이 발생하지 않는다.
연구 영역과 상용 영역
연구(Research) 영역에서는 모델의 정확도, 그리고 모델의 성능에 관심이 많지만, 실재 상용(Production) 관점에서는 세일즈맨은 세이즈 포인트에 관심을 두고, 소비자는 AI 시스템이 좀 더 생활에 유용하기를 바라고, 다양한 관점으로 AI 시스템을 이용한다.
상용 관점에서는 대기시간(latency)가 짧은 것과 Throughput(처리량)에 대한 처리가 많은 것이 중요하다. 대기 시간은 시스템이 응답하기까지의 지연시간을 의미한다. 처리량은 1초 안에 얼마나 많은 일을 할 수 있는지와 관련되어 있다.
신뢰할만한 AI 시스템
신뢰할만한 AI 시스템은 다음과 같은 요소를 고려한다.
- Reliability: 데이터 응답이 신뢰할 만해야 한다. 모델 자체의 성능과 관련 되어 있다.
- Scalability: 요청에 따라 규모를 확장할 수 있는 형태로 시스템 내부 요소들이 연길되도록 설계 해야한다.
- Maintainability: 손쉽게 모델 업데이트가 지속적으로 가능해야한다.
예측의 두가지 방식
AI 시스템이 결과를 예측하는 방법에는 배치 예측(batch prediction)과 온라인 예측(onlie prediction) 방법이 존재한다. 배치 예측은 대량의 데이터가 존재하고 이를 모델에 반영하기까지 시간이 걸려, 일정 주기 정책에 따라 예측 결과를 생성해 두었다가 결과를 내놓는 방식이다. 좀 더 복잡한 모델인 경우 시간이 오래 걸릴 수 있어 배치 예측 방식으로 결과를 제공하고 있다. 온라인 예측은 상대적으로 덜 복잡한 예측에 대해서 미리 준비된 모델로 요청 시 마다 결과를 내놓는 방식이다. 대부분 상용 서비스는 이러한 온라인 예측 방식으로 예측 결과를 제공하고 있다. 검색어 자동 추천과 같은 것이 예이다.
이 둘간을 비교하자면 다음과 같다.
| 배치 예측 | 온라인 예측 | |
|---|---|---|
| 예측 주기 | 일정 시간 마다(precomputed and stored) | 요청시 |
| 최적화 관점 | 높은 throughput 필요 | Low 레이턴시 필요 |
| 예측 다양성 | 예측 가능한 범위내에서 예측 | 예측 가능한 범위가 무한대에 가까운 |
| 예제 | 넷플릭스 컨텐츠 추천, 숙박 업소 랭킹 추천, 관련 상품 추천, 검색어 추천 | 음성 인식, 사용자 맛집 추천, 상품평 요약, 주식 주가 예측 |
위 두가지 방식은 Hybrid 방식으로 섞어 사용할 수 있다. 예를 들어서 숙박 업소 랭킹 추천 목록은 배치 예측을 적용할 수 있지만, 각 숙박 업소의 사용자가 좋아할만한 맛집 추천 등은 온라인으로 추천하는 방식과 같은것이다.
응용예
-
구글 Vertext AI에서는 TensorFlow, scikit-learn, XGBoost와 같은 머신러닝 프레임워크와 결합해 예측 모델을 생성하고 배포할 수 있는 플랫폼을 제공하고 있다.